



Creating a Database
This guide explains how to create a new managed database instance using the AppsCode console. The creation process is a multi-step wizard that walks you through selecting a database engine, setting a name and namespace, configuring topology and resources, and enabling optional features like monitoring, TLS, and backups.
1. Getting Started
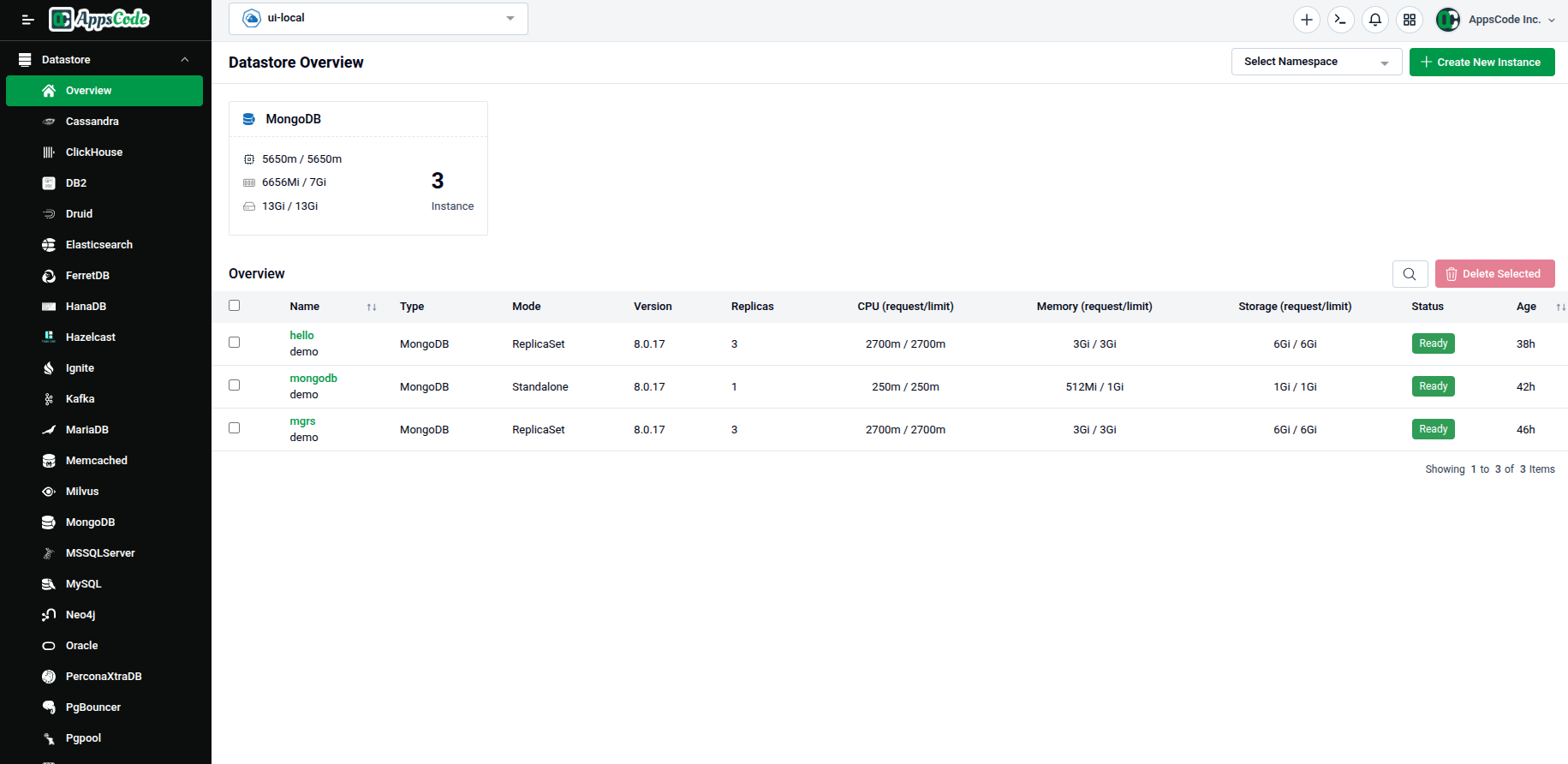
Navigate to the Datastore section in the left sidebar. The Datastore Overview page lists all existing database instances across your connected engines.
To create a new database, click the green + Create New Instance button in the top-right corner of the page.
2. Select a Database Type
You will be presented with a grid of all supported database engines. Click on the engine you want to provision.
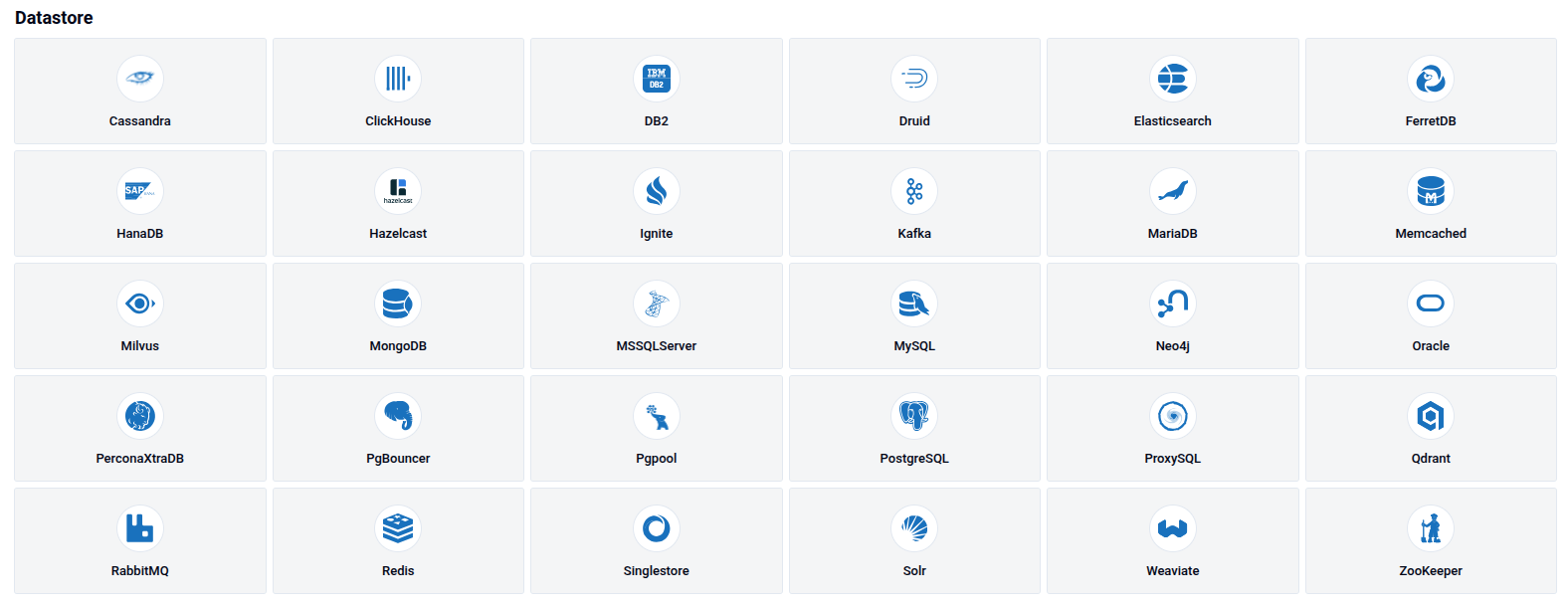
Tip: The console supports a wide range of engines including relational, document, key-value, search, and time-series databases. Select the engine that best fits your workload.
3. Choose Namespace and Name
After selecting the database type, you will be prompted to choose a namespace and provide a name for the new instance.
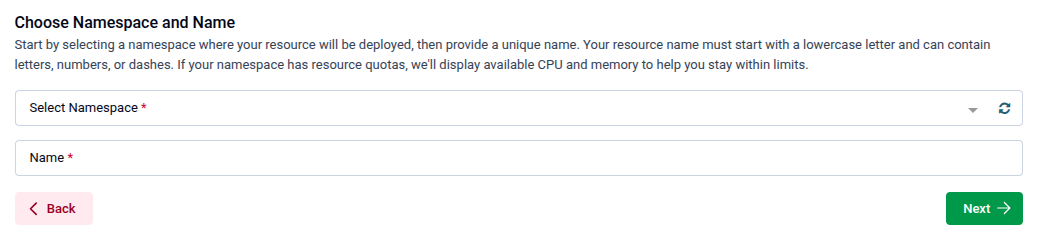
- Select Namespace: Choose the Kubernetes namespace where the database will be deployed. If the namespace has resource quotas, available CPU and memory will be shown to help you stay within limits.
- Name: Enter a unique name for the database instance. The name must start with a lowercase letter and can contain letters, numbers, or dashes.
Click Next to proceed to the configuration step.
Note: Both fields are required (marked with a red asterisk). The name cannot be changed after creation.
4. Configure the Database
The main configuration page shows all settings for the new database. At the top, the namespace and name you chose are displayed as a breadcrumb (e.g., demo / mongo-test).
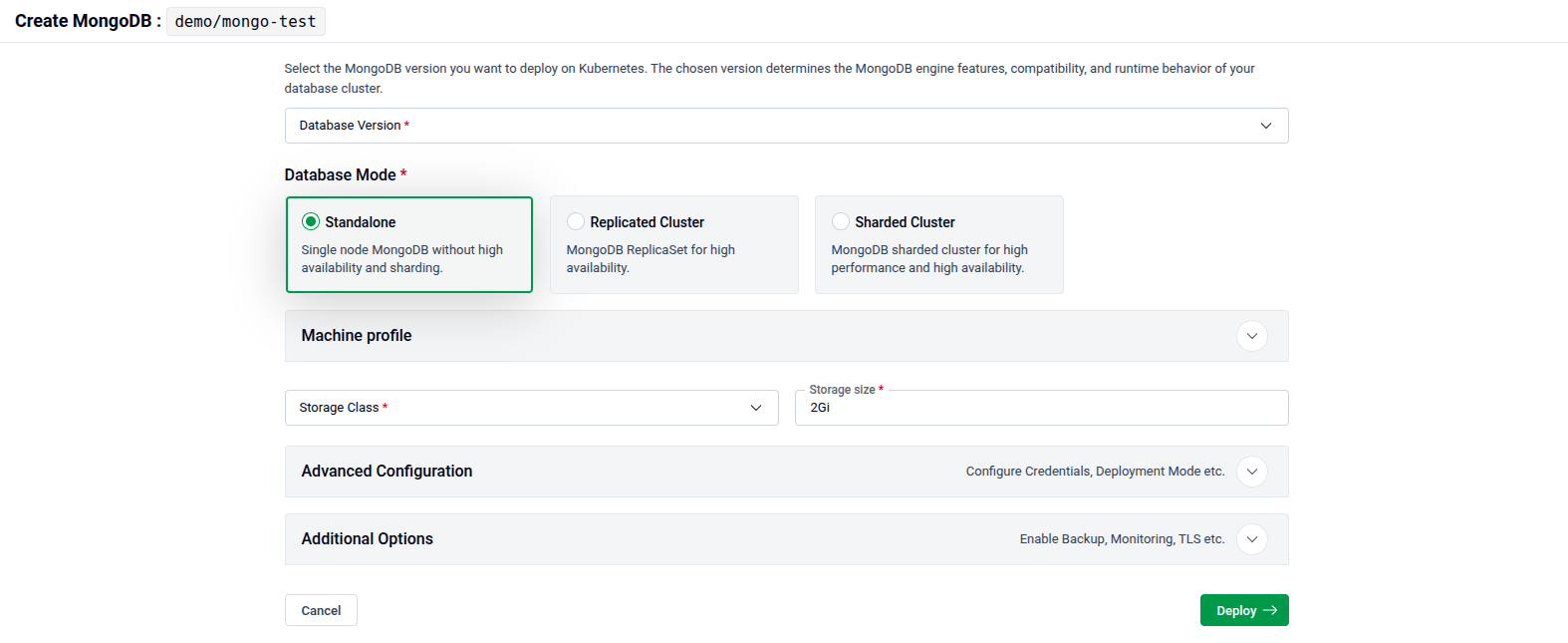
4.1 - Database Version
Select the database engine version from the Database Version dropdown. The version determines the engine features, compatibility, and runtime behaviour of your cluster.
4.2 - Database Mode
Select the topology for your database under Database Mode. Three modes are available:
- Standalone — A single-node database without high availability or sharding. Best for development or low-traffic workloads.
- Replicated Cluster — A MongoDB ReplicaSet for high availability.
- Sharded Cluster — A fully sharded MongoDB cluster for high performance and high availability.
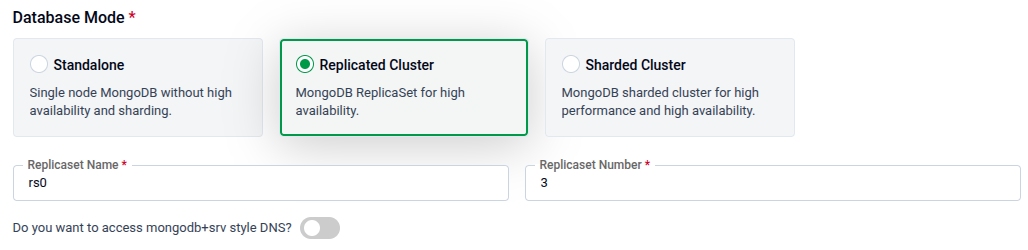
Replicated Cluster
When Replicated Cluster is selected, two additional fields appear:
| Field | Description |
|---|---|
| Replicaset Name | The name for the replica set (e.g., rs0). Required. |
| Replicaset Number | The number of replica members (e.g., 3). Required. |
| mongodb+srv style DNS | Toggle on to enable mongodb+srv connection string support for this replica set. |
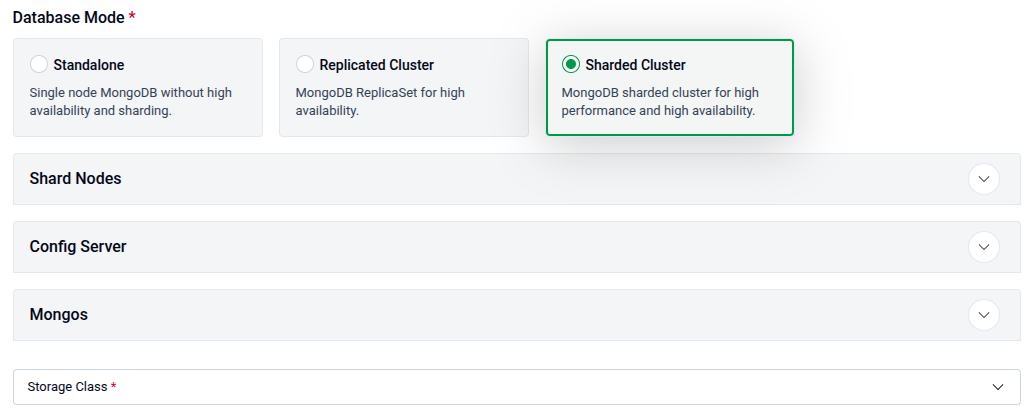
Sharded Cluster
When Sharded Cluster is selected, three subsections appear — Shard Nodes, Config Server, and Mongos — each configurable independently.
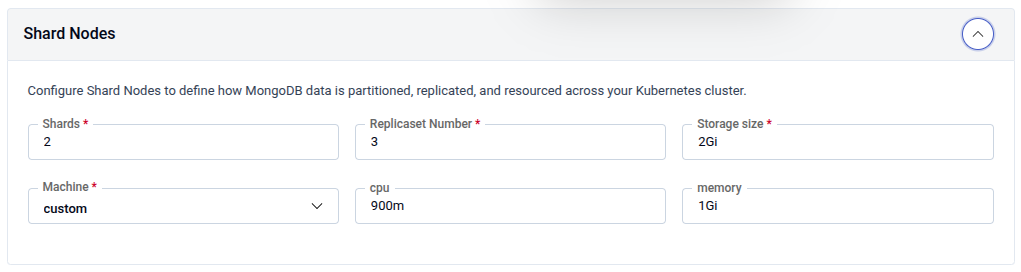
Shard Nodes — Configure how MongoDB data is partitioned, replicated, and resourced across your cluster.
| Field | Description |
|---|---|
| Shards | Number of shard partitions (e.g., 2). Required. |
| Replicaset Number | Number of replicas per shard (e.g., 3). Required. |
| Storage size | Disk size per shard node (e.g., 2Gi). Required. |
| Machine | Preset machine profile or custom for manual CPU/memory. |
| CPU | CPU request per shard node (e.g., 900m). |
| Memory | Memory request per shard node (e.g., 1Gi). |
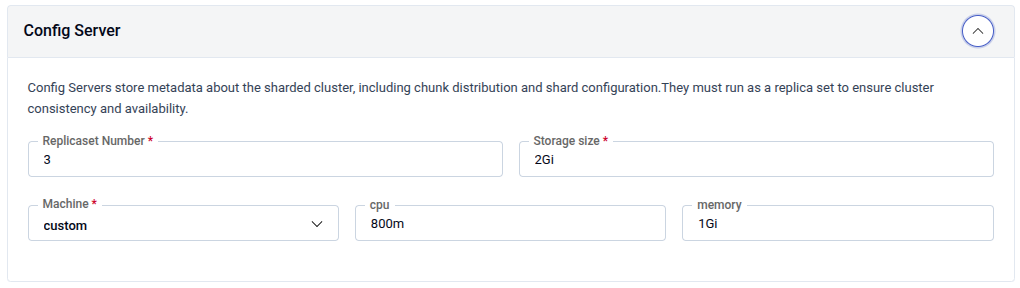
Config Server — Stores metadata about the sharded cluster including chunk distribution and shard configuration. Must run as a replica set.
| Field | Description |
|---|---|
| Replicaset Number | Number of config server replicas (e.g., 3). Required. |
| Storage size | Disk size per config server node (e.g., 2Gi). Required. |
| Machine | Preset machine profile or custom. |
| CPU | CPU request (e.g., 800m). |
| Memory | Memory request (e.g., 1Gi). |
Mongos — Acts as the query router for the sharded cluster, directing client requests to the appropriate shards based on metadata from Config Servers.
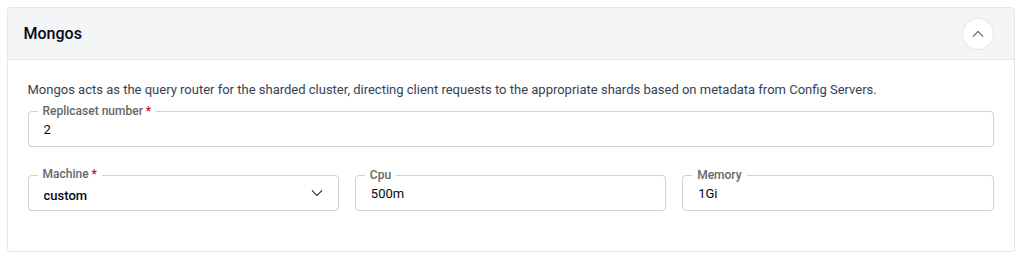
| Field | Description |
|---|---|
| Replicaset number | Number of Mongos router instances (e.g., 2). Required. |
| Machine | Preset machine profile or custom. |
| CPU | CPU request (e.g., 500m). |
| Memory | Memory request (e.g., 1Gi). |
4.3 - Machine Profile
The Machine Profile dropdown lets you select a preset CPU and memory configuration for your database nodes. Choose custom to enter specific CPU and memory values manually.
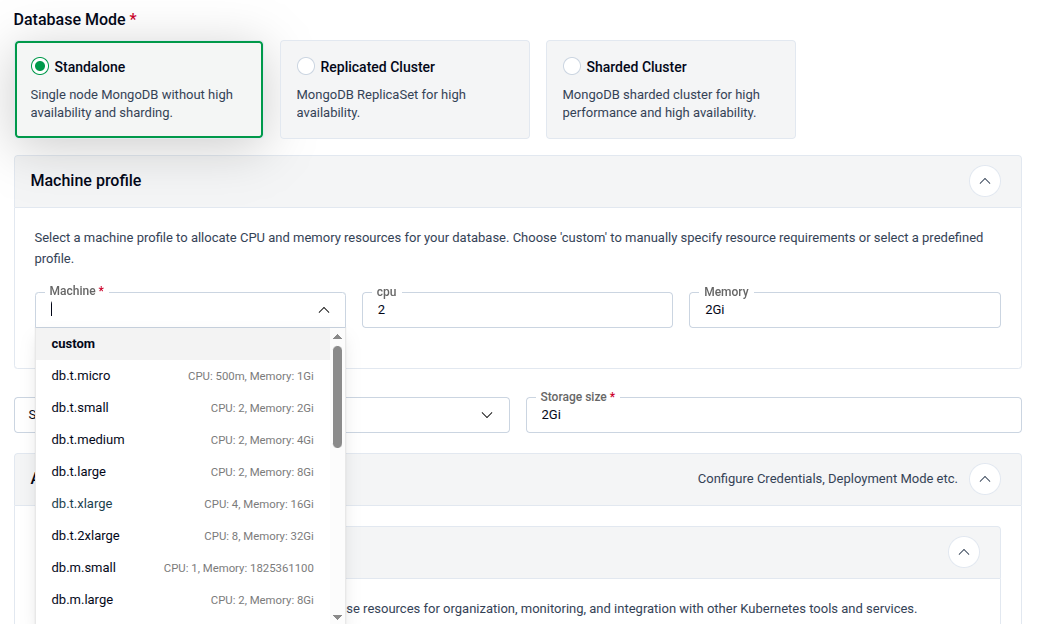
Tip: Preset profiles are named by size (e.g.,
db.t4large). Usecustomwhen your workload requires resources that do not match any preset.
4.4 - Storage Class and Size
Select the Kubernetes Storage Class that will back the database persistent volumes, and enter the required Storage size.

| Field | Description |
|---|---|
| Storage Class | The Kubernetes StorageClass for persistent volumes (e.g., longhorn). Required. |
| Storage size | The disk capacity to allocate per node (e.g., 2Gi). Required. |
5. Advanced Configuration
Expand the Advanced Configuration panel (labelled Configure Credentials, Deployment Mode etc.) to access additional settings.
5.1 - Labels & Annotations
Add custom Kubernetes labels and annotations to the database resources for organization, monitoring, and integration with other tools and services.
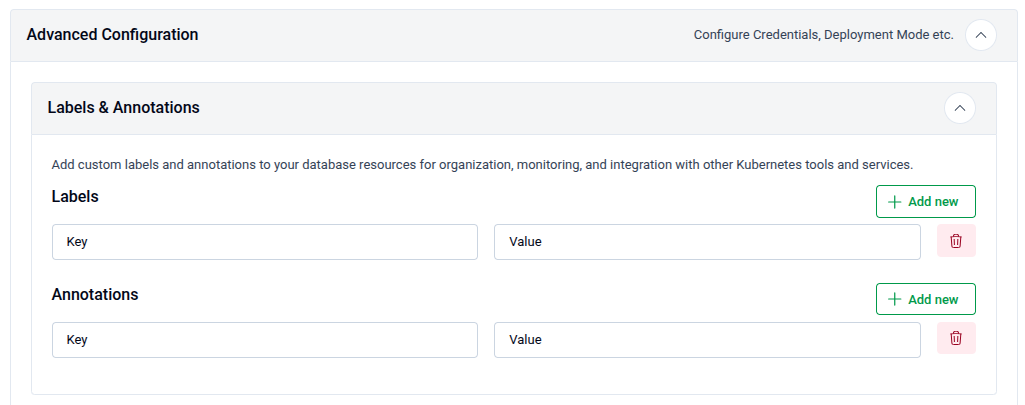
- Use + Add new under Labels to attach key-value label pairs.
- Use + Add new under Annotations to attach key-value annotation pairs.
- Use the delete icon on any row to remove it.
5.2 - Deletion Policy
The Deletion Policy dropdown controls what happens to the database resources when the database object is deleted from Kubernetes.

| Option | Behaviour |
|---|---|
| Delete | Deletes the database pods and services but retains the PersistentVolumeClaims. |
| Halt | Stops the database without deleting any resources. Can be resumed later. |
| WipeOut | Deletes all resources including PersistentVolumeClaims. All data is permanently removed. |
| DoNotTerminate | Prevents deletion — the database cannot be removed until this policy is changed. |
Warning: WipeOut permanently destroys all data. Ensure you have a valid backup before selecting this policy.
5.3 - Authentication Credentials
Configure how the database root credentials are managed.
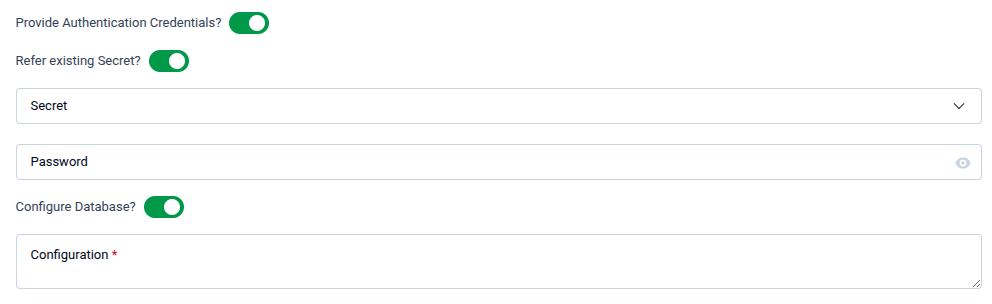
| Field | Description |
|---|---|
| Provide Authentication Credentials | Toggle on to supply custom credentials instead of auto-generating them. |
| Refer existing Secret | Toggle on to reference an existing Kubernetes Secret for credentials. Select the secret from the dropdown. |
| Password | Manually enter a password if not using an existing Secret. |
| Configure Database | Toggle on to provide a custom database configuration. Enter the configuration in the Configuration textarea (required when enabled). |
5.4 - Point in-time Recovery
Enable Point in-time Recovery to restore the new database from a previous backup to an exact timestamp.
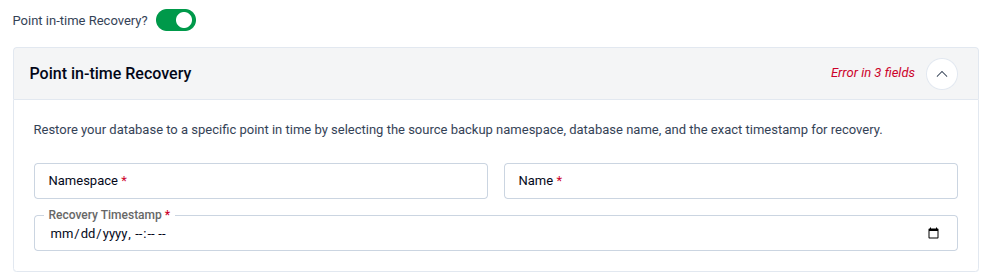
- Namespace: The namespace where the source backup resides. Required.
- Name: The name of the source database to recover from. Required.
- Recovery Timestamp: The exact date and time to restore to (
mm/dd/yyyy, hh:mm). Required.
Note: All three fields are required when Point in-time Recovery is enabled. Leaving any field empty will show an "Error in fields" warning.
6. Additional Options
Expand the Additional Options panel (labelled Enable Backup, Monitoring, TLS etc.) to enable integrated platform features for the new database.
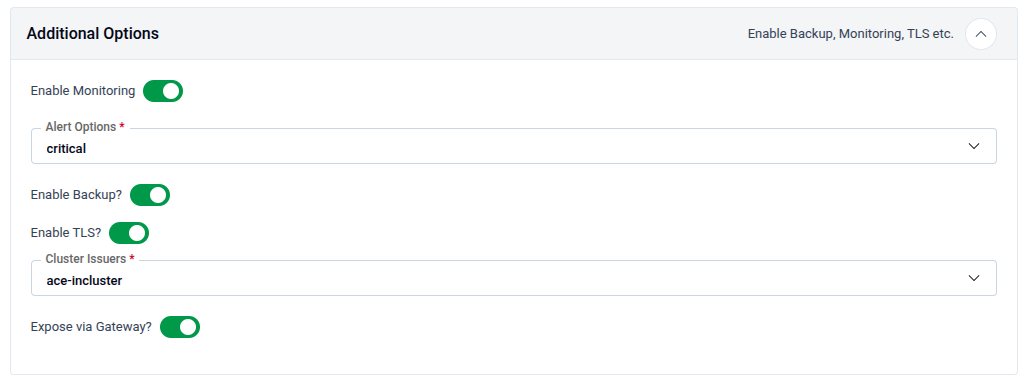
| Option | Description |
|---|---|
| Enable Monitoring | Enables Prometheus metrics collection. Select an Alert Options level (critical, warning, info) to control which alerts are fired. |
| Enable Backup | Registers the database with the backup system so scheduled backups can be configured after creation. |
| Enable TLS | Enables TLS encryption. Select a Cluster Issuer from the dropdown (e.g., ace-incluster) to sign the certificates. |
| Expose via Gateway | Toggles external access through the configured gateway endpoint. |
7. Deploy
Once all required fields are filled and options are configured, click the green Deploy button at the bottom-right of the form to create the database.
Note: Required fields are marked with a red asterisk. The Deploy button will be active only when all required fields are valid. If any field has an error, a validation summary will appear above the button.
Quick Reference
| Action | Where / How |
|---|---|
| Start creating a database | Datastore Overview → + Create New Instance |
| Select database engine | Click the desired engine from the type grid |
| Set namespace and name | Choose Namespace and Name step → fill both fields → Next |
| Use a single node | Database Mode → Standalone |
| Create a replica set | Database Mode → Replicated Cluster → set Replicaset Name and Number |
| Create a sharded cluster | Database Mode → Sharded Cluster → configure Shard Nodes, Config Server, Mongos |
| Set CPU and memory | Machine Profile → select preset or choose custom |
| Set storage | Storage Class → select class → set Storage size |
| Add labels or annotations | Advanced Configuration → Labels & Annotations → + Add new |
| Control deletion behaviour | Advanced Configuration → Deletion Policy → select option |
| Provide custom credentials | Advanced Configuration → toggle Provide Authentication Credentials |
| Restore to a point in time | Advanced Configuration → toggle Point in-time Recovery → fill Namespace, Name, Timestamp |
| Enable monitoring | Additional Options → toggle Enable Monitoring → set Alert Options |
| Enable backup at creation | Additional Options → toggle Enable Backup |
| Enable TLS at creation | Additional Options → toggle Enable TLS → select Cluster Issuer |
| Expose via gateway | Additional Options → toggle Expose via Gateway |
| Apply and create | Click Deploy |