










KubeDB Health Checker
In KubeDB v2022.08.08
, we’ve improved KubeDB database health checks and users can now control the behavior of the health checks performed by KubeDB. We’ve added a new field called healthChecker under spec. It controls the behavior of health checks. It has the following fields:
spec.healthChecker.periodSecondsspecifies the interval between each health check iteration.spec.healthChecker.timeoutSecondsspecifies the timeout for each health check iteration.spec.healthChecker.failureThresholdspecifies the number of consecutive failures to mark the database as NotReady.spec.healthChecker.disableWriteCheckspecifies if you want to disable database write check, by default KubeDB performs write check.
For example, the healthChecker section of a KubeDB database yaml looks like this:
spec:
healthChecker:
periodSeconds: 15
timeoutSeconds: 10
failureThreshold: 3
disableWriteCheck: true
If you provide the above health checker configuration in your KubeDB database yaml, health check will be performed like the following:
- A health check will be performed every
15 secondsfor your database. - If a health check takes more than
10 seconds, that health check will be timed out and will be considered as failed. - If a particular health check, say creating a database client, fails for
3 timesonly then the database will be considered asNotReady. But if the number of failures is less than 3 then the database won’t be considered asNotReady. - Write check won’t be performed for the database.
How does KubeDB Health Checker Work?
Now, let’s see how the KubeDB health check is performed by the operator. We can describe the health check in the following way. First, we can see how the phase is calculated using 2 status conditions of the database object. Then we can see how these conditions are calculated.
How DB Phase is calculated?
The flowchart below shows how KubeDB calculates the database Phase.
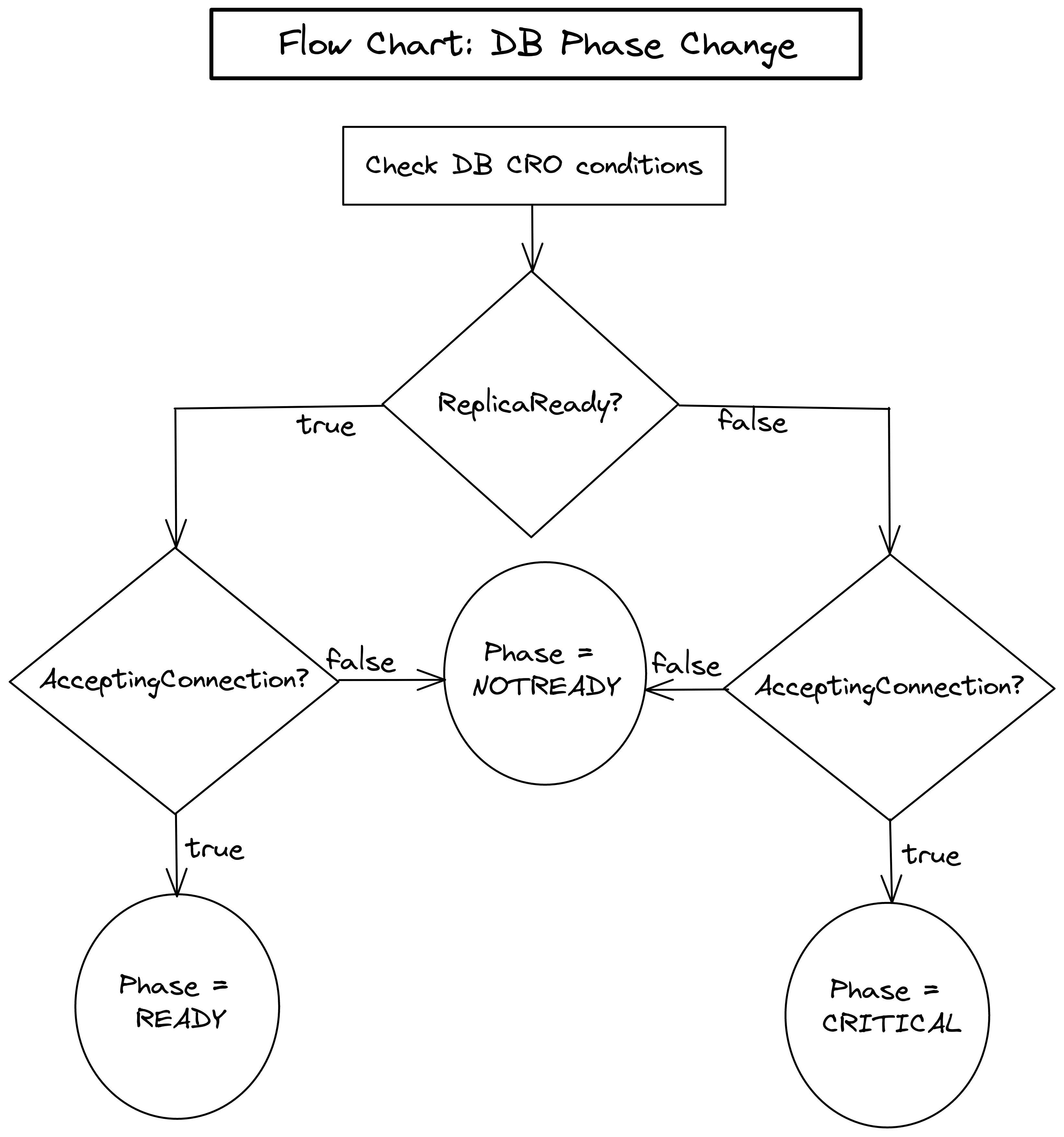
The flowchart shows that KubeDB checks the status conditions of the database objects.
- First, it checks the
ReplicaReadycondition. - Then, it checks the
AcceptingConnectioncondition. - If both of the conditions are true, KubeDB sets the database phase as
Ready. - If
ReplicaReadyis false, butAcceptingConnectionis true, the database phase is set toCritical. - If
AcceptingConnectionis false, irrespective of theReplicaReadyconditions the database is set toNotReady.
The below table shows the currently supported KubeDB phases and what each phase means:
| Phases | Reason | DB Usable |
|---|---|---|
| Provisioning | Databases are currently provisioning | ❌ |
| DataRestoring | Databases for which data is currently restoring | ✅ |
| Ready | Databases that are currently ReplicaReady, AcceptingConnection | ✅ |
| Critical | Clients can connect to database but one or more replicas are not ready (via watching statefulsets) | ✅ |
| NotReady | Databases that can’t connect (either connect, ping, write or other checks failed) | ❌ |
| Halted | Databases that are halted (Pods deleted, PVCs exist) | ❌ |
| Unknown | Health checker has been disabled (happens during horizontal scaling) | ❓ |
How ReplicaReady condition is determined?
The flowchart below shows how KubeDB determines the ReplicaReady condition.
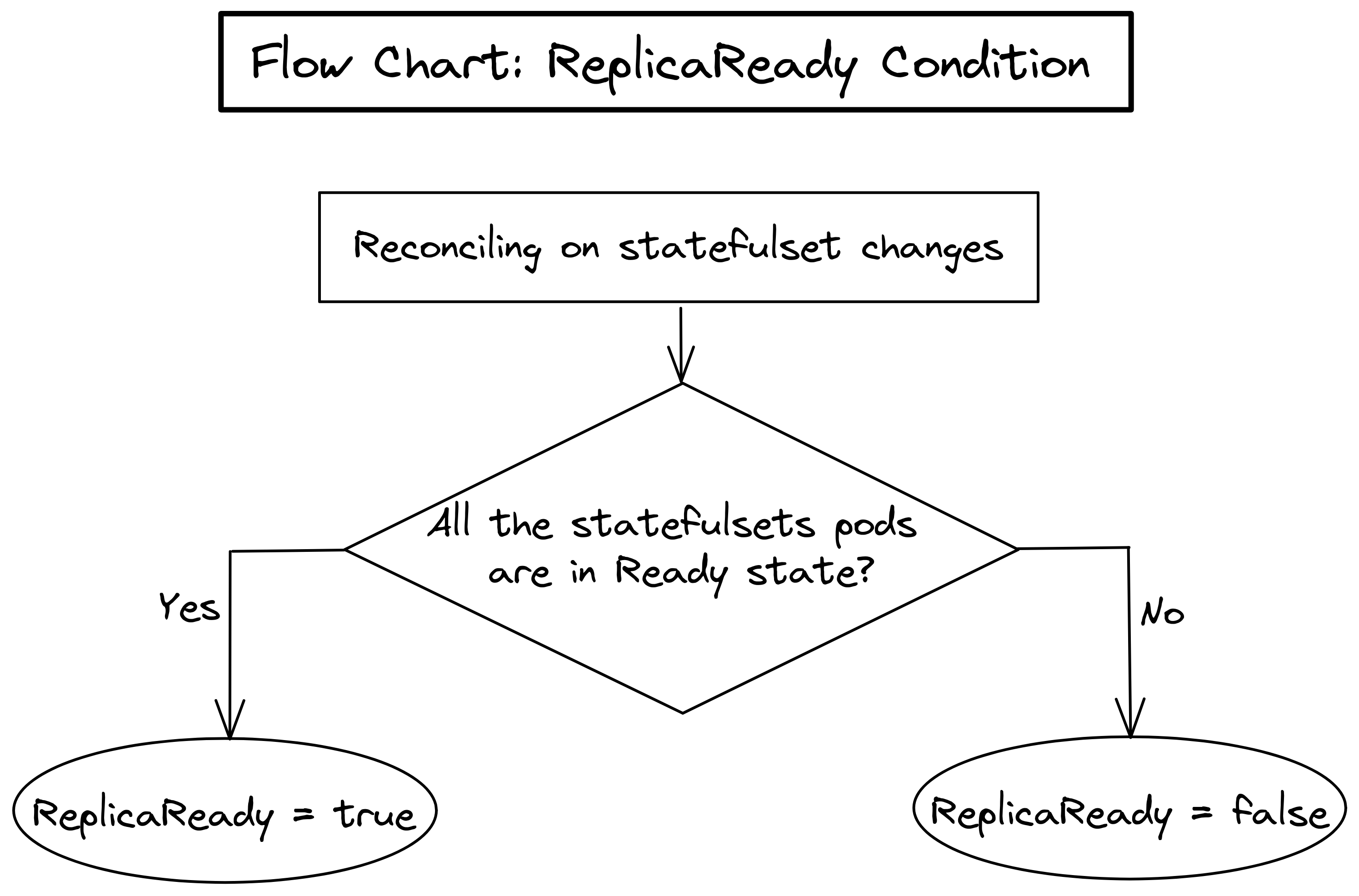
We can see from the flowchart that, When a database StatefulSets have any changes, the operator checks if all the Pods of that StatefulSet are in Ready state.
- If all the Pods are in Ready state, the
ReplicaReadycondition is set to True. - Otherwise, the
ReplicaReadycondition is set to False.
How AcceptingConnection condition is determined?
The flowchart below shows how KubeDB determines the AcceptingConnection condition.
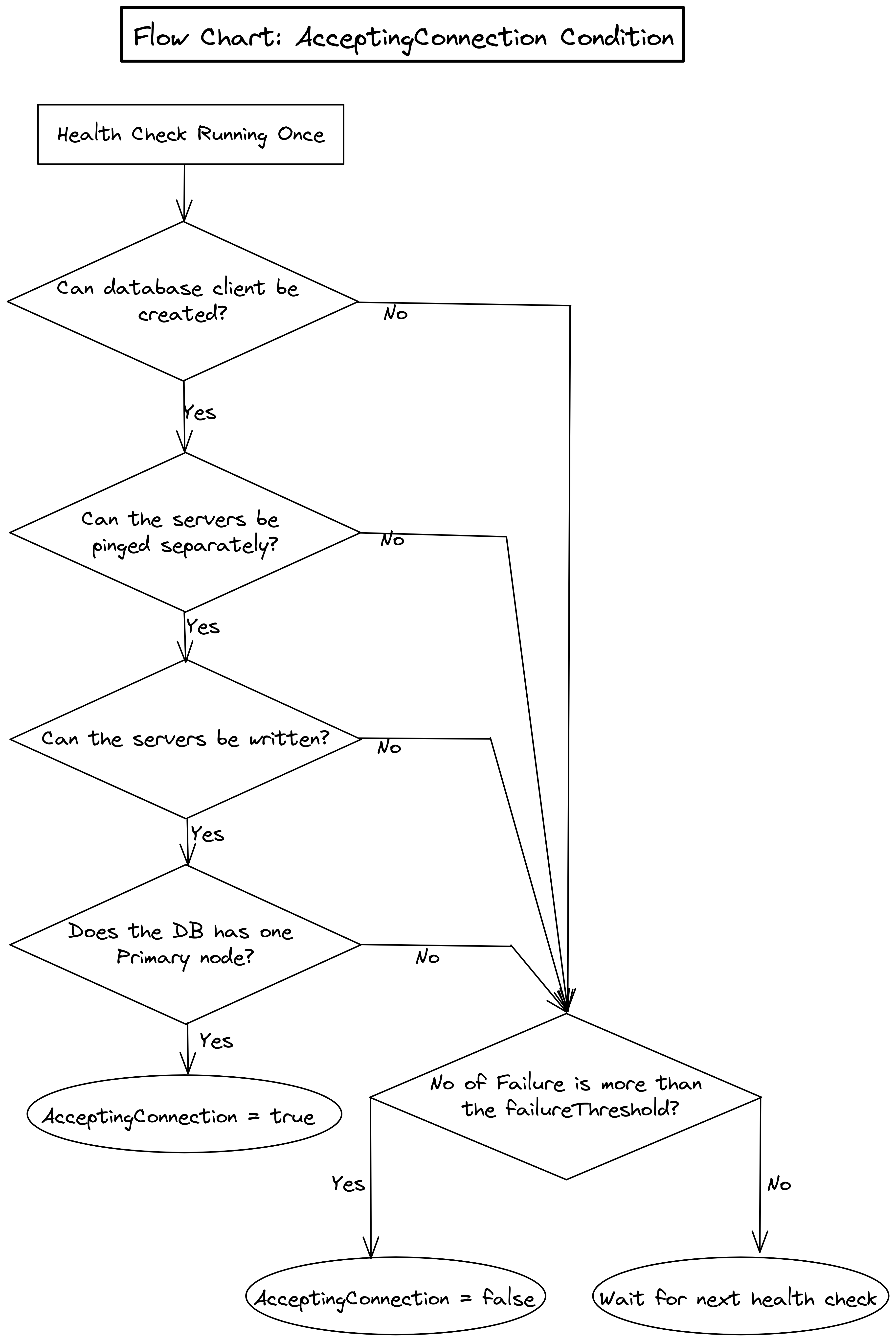
From the flowchart we can see that, on each health check, KubeDB performs the following checks:
- Can a database client be created?
- Can the database servers be pinged using the created client?
- If
disableHealthCheckis not true, can the database be written to? - If the database is in cluster mode with primary and secondary nodes, Is there only one Primary node?
If all the answers are affirmative, KubeDB sets the AcceptingConnection condition as True.
But, if any of the checks failed, KubeDB checks how many times that particular check failed before. If the number of failures crosses the failureThreshold provided by the user, KubeDB sets the AcceptingConnection condition as False.
So, using the AccptingConnection and ReplicaReady conditions, KubeDB determines the database phase and the phase reflects the current health of the Database.
Support
To speak with us, please leave a message on our website .
To receive product announcements, follow us on Twitter .
If you have found a bug with KubeDB or want to request for new features, please file an issue .